
With the development of machine learning, demand for AutoML (Automatic Machine Learning) increases. This article split this topic into two, namely AutoML in classic machine learning and that in deep learning.
After completing this tutorial, you will know:
- AutoML in both classic and deep machine learning.
- A peek of two open-source frameworks, Auto-Sklearn and Auto-Keras.
- Two algorithms, Bayesian Optimization and Network Morphism.
- The ideas behind Neural Architecture Search.
AutoML in Classic Machine Learning
CASH
AutoML has many sub-functionalities, including automatic data analysis, automatic feature engineering, automatic normalization and regularization, automatic feature selection, automatic algorithm selection and automatic hyperparameter optimization(HPO). Recent studies focus on the CASH[1] problem. That is Combined Algorithm and Selection and Hyperparameter Optimization.
CASH was proposed by Thornton in Auto-Weka[1]. The solution he provided was Bayesian Optimization[2].
Bayesian Optimization
Bayesian Optimization (BO) is one of the means we find extrema (both max and min values) in a function. Other options may include grid search, random search and gradient descent. Compared to gradient descent, BO optimizes functions that are non-convex and non-derivative.
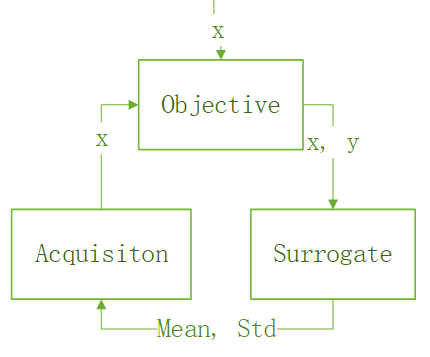
In BO, we call the black-box function we optimize the objective function. This function is usually costly to run. Thus, we introduce the surrogate function to estimate the mean and standard deviation of the objective function. The output is then used by the acquisition function in searching for the next sample to exploit or explore.
The BO searches for extrema in a finite search space.
The process is summarized as follow:
- Sample some points x in the search space.
- Find the corresponding y by the objective function.
- update the surrogate function using x, y.
- find the next x using the acquisition function.
- Goto 2 unless finding extrema.
The following flowchart demonstrates the process.
Now let’s look at an example. Suppose we have the following function:
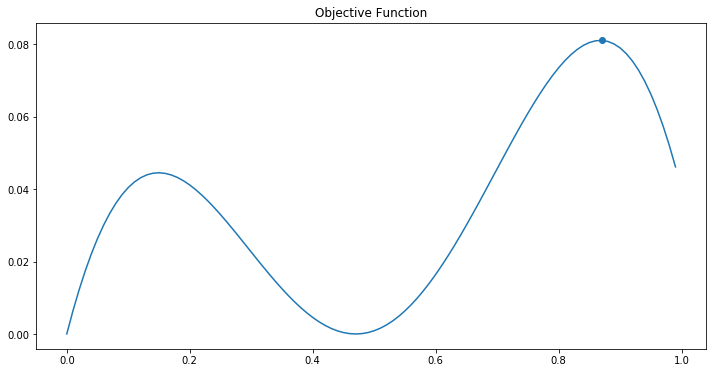
The search space is [0, 1]. Firstly two points x=0 and x=1 are selected, and their y values are calculated using the objective function.
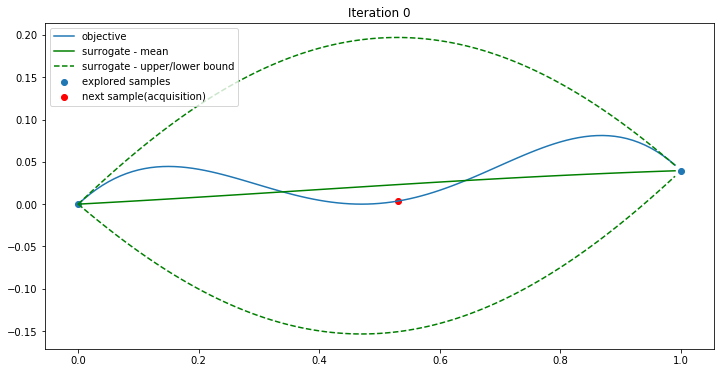
Then the mean and standard deviation are generated by the Gaussian process or the surrogate function. The UCB (Upper Confidence Bound) algorithm is used as the acquisition function. It simply takes the max value of the upper confidence bound (red in the plot) as the next sample point.
The BO continues…
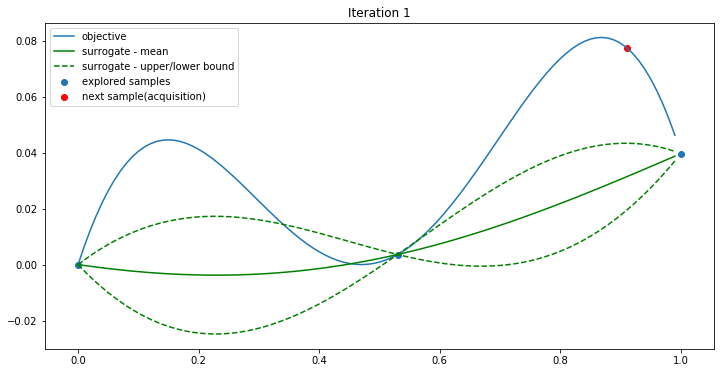
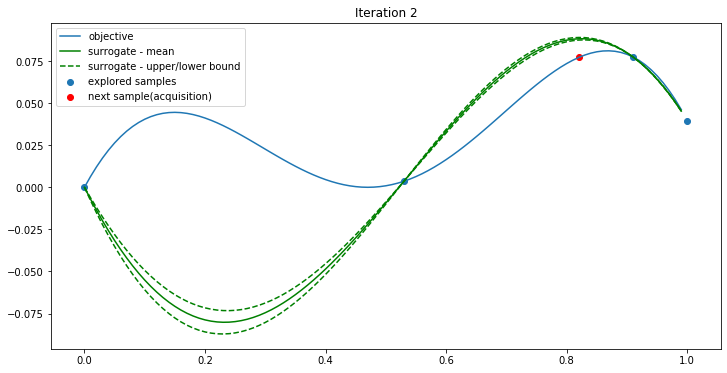
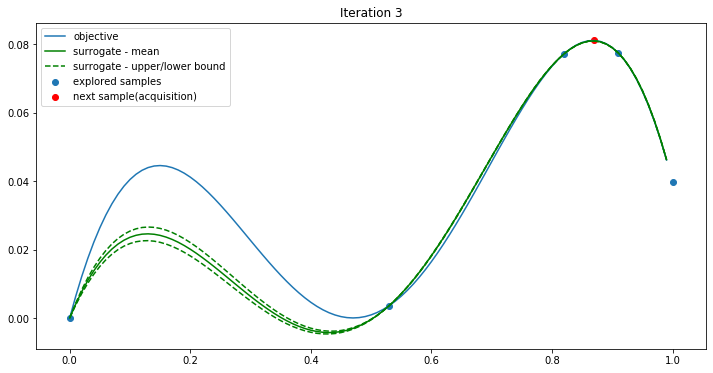
After four iterations, the max value is found.
The above pictures were generated by a notebook from my Github Repo Machine Learning Step by Step.
Auto-Sklearn
Auto-Sklearn[3] used Bayesian Optimization to find the best hyperparameters for machine learning. Besides that, it proposed two new improvements. The first is meta-learning. Auto-Sklearn collected several datasets, extracted features from these datasets. These datasets are trained and the best hyperparameters are collected. The dataset features and best hyperparameters are treated as input and output for machine learning and the relationship is learned. Thus, the search space is narrow and the algorithm runs faster. The second improvement is ensemble. As we all know ensemble improves accuracy.
I installed Auto-Sklearn. The Titanic Survive and Boston House Price datasets are used. Each took one hour to finish on an i7 CPU. The scores are 0.76 and 0.85. Not too bad.
Auto-Sklearn focuses on the CASH problem. it does not handle data preprocessing. I have to remove string features like names and tickets in advance. Categorical features like embarking place, gender have to be transformed into Boolean values or one-hot values.
Sample code for auto-sklearn
1 | import autosklearn.classification |
Official Website: https://automl.github.io/auto-sklearn/master/
Deep Learning in AutoML
Neural Architecture Search
Neural Architecture Search (NAS) is the main research topic in deep learning automation. The rough idea is to treat deep models as strings such that the next layer can be predicted by RNN. NAS named this RNN the controller. The original NAS used reinforcement learning to optimize the parameters.
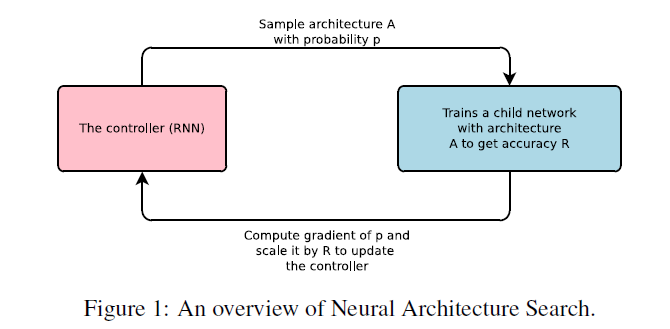
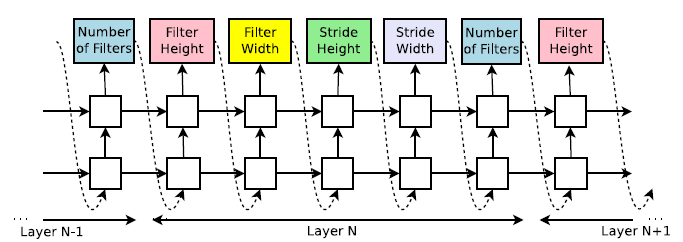
Some architectures have branches. NAS uses a batch of bi-classifiers to determine if Layer N connects to one of the N-1 layers.
The following are the original LSTM (upper left) and two LSTM structures NAS found.
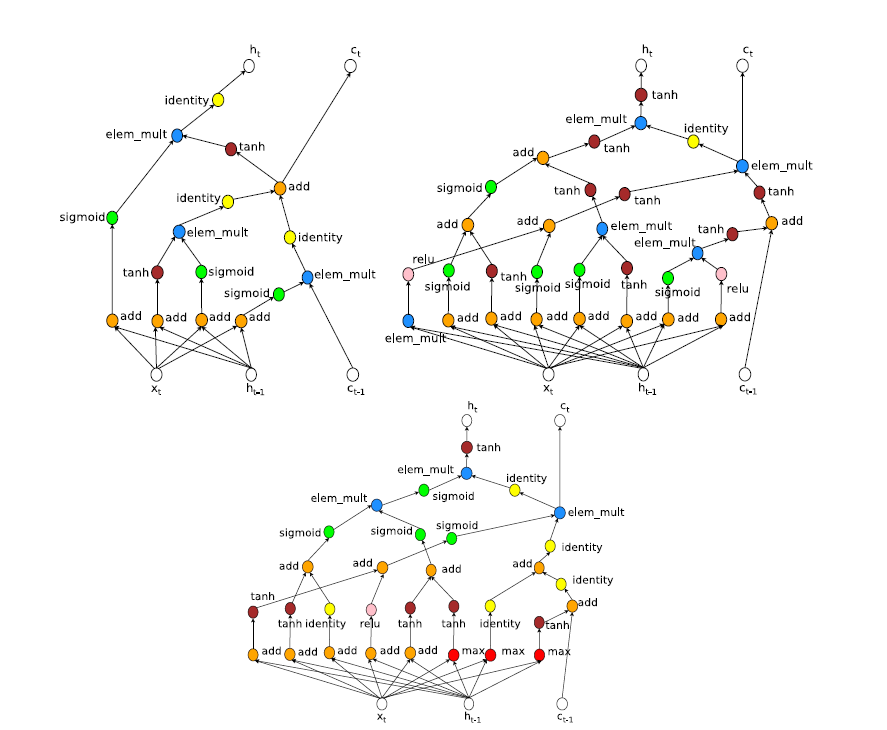
Xin He[5] summarized all the NAS works. For controllers, grid search, random search, reinforcement learning, evolution algorithm, Bayesian optimization, gradient descent are used. Low fidelity, transfer learning, surrogate, early stopping are used to perform more efficiently.
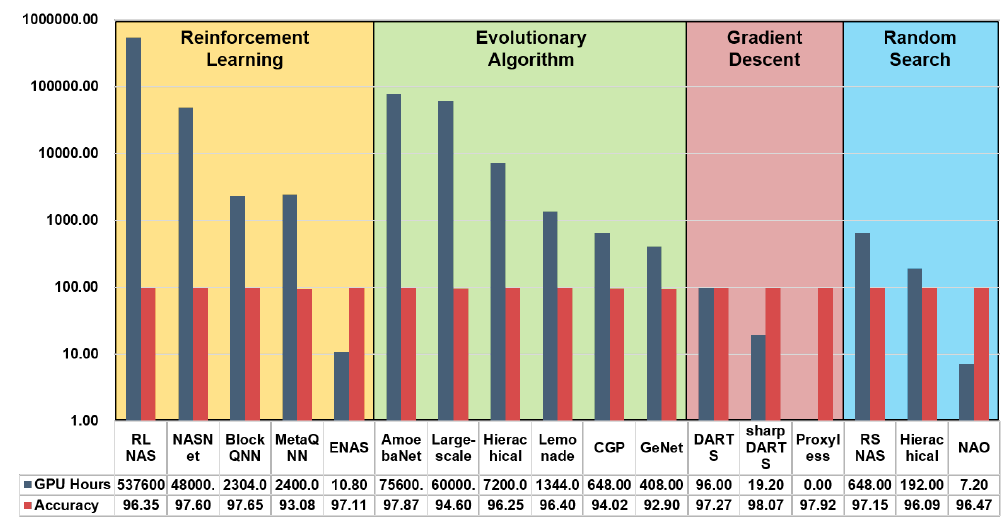
The following is a comparison of all the NAS implementations:
Network Morphism
In the process of NAS, a great number of architectures are tested. If the new network can learn parameters from the old ones, it would be more efficient. Network Morphism[6] provides such a mechanism. Network Morphism named the old and new network the parent network and the child network. The child network inherits knowledge from the parent network.
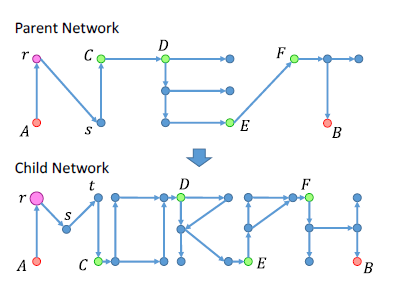
There are five cases in Network Morphism, linear, non-linear, stand-alone width, stand-alone kernal, and subnet.
Linear Case
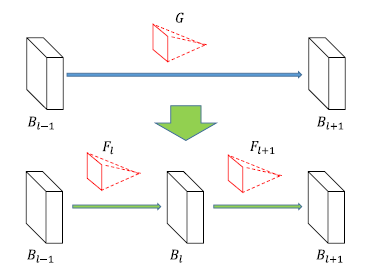
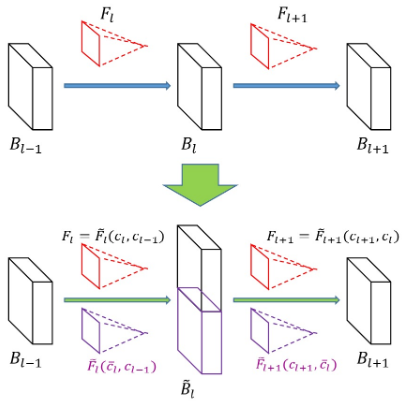
A new layer, Layer L is inserted between Layer L-1 and Layer L+1. Bl-1 and Bl+1 are two matrices and Bl+1=Bl-1 * G. To insert a new layer, we simply split G into two matrices, Fl and Fl+1 .
Non-Linear Case
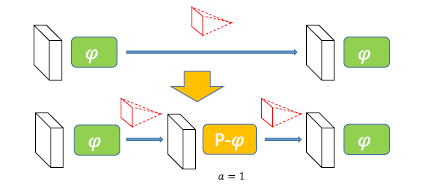
To insert a non-linear layer between two layers, a new activation function, parametric activation is introduced. It starts as an Identity matrix and learns to become an activation function afterward. It is a wrapper around other activation functions. The equation is as follow:
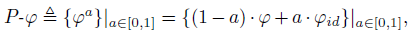
Stand-alone Width
We calculate the equations from the above chart. We finally will have the following:
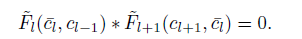
Kernal
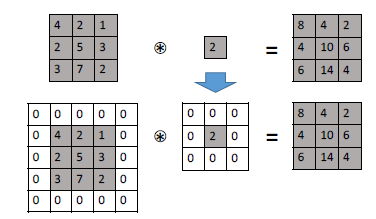
For kernals, we simply do padding.
Subnet
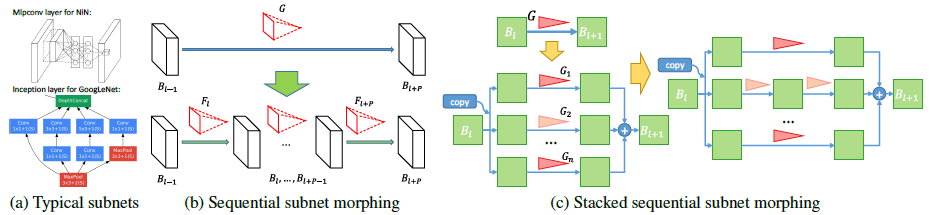
Firstly, we insert the layers one by one. this is sequential subnet morphing. We then stack them by simply split G into a group of G, each is G/n.
Auto-Keras
Auto-Keras is an opensource based on Keras. It uses Bayesian optimization and network morphism. It trains CNN, RNN and traditional DNN.
Sample code:
1 | import autokeras as ak |
The official website:
Where to use AutoML?
AutoML is suitable in some mature scenarios, like traditional ML, image recognition, object detection, OCR, text analysis, etc.. The reason is that we have limit options.
For problems like audio-related research, because it is not mature, what is to try is not clear. Thus it is not possible to use autoML.
Reference
[1] C. Thornton, F. Hutter, H. Hoos, and K. Leyton-Brown. Auto-WEKA: combined selection and hyperparameter optimization of classification algorithms. In Proc. of KDD’13, pages 847–855, 2013.
[2] E. Brochu, V. Cora, and N. de Freitas. A tutorial on Bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning. CoRR, abs/1012.2599, 2010.
[3] Efficient and Robust Automated Machine Learning, Feurer et al., Advances in Neural Information Processing Systems 28 (NIPS 2015).
[4] Zoph, Barret, and Quoc V. Le. “Neural Architecture Search with Reinforcement Learning.” arXiv: Learning (2016).
[5] He, Xin, Kaiyong Zhao, and Xiaowen Chu. “AutoML: A Survey of the State-of-the-Art..” arXiv: Learning (2019).
[6] Wei, Tao, et al. “Network morphism.” international conference on machine learning (2016): 564-572.