
The Gradient Boosting (GB) algorithm trains a series of weak learners and each focuses on the errors the previous learners have made and tries to improve it. Together, they make a better prediction.
According to Wikipedia, Gradient boosting is a machine learning technique for regression and classification problems, which produces a prediction model in the form of an ensemble of weak prediction models, typically decision trees. It builds the model in a stage-wise fashion as other boosting methods do, and it generalizes them by allowing optimization of an arbitrary differentiable loss function.
Prerequisite
1. Linear regression and gradient descent
2. Decision Tree
3. Gradient Boosting Regression
After studying this post, you will be able to:
1. Explain gradient boosting algorithm.
2. Explain gradient boosting classification algorithm.
3. Write a gradient boosting classification from scratch
The algorithm
The following plot illustrates the algorithm.
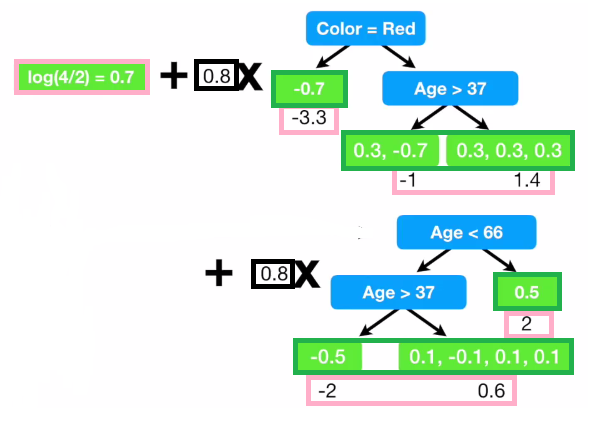
(Picture taken from Youtube channel StatQuest)
From the plot above, the first part is a stump, which is the log of odds of y. We then add several trees to it. In the following trees, the target is not y. Instead, the target is the residual or the true value subtracts the previous prediction.
That is why we say in Gradient Boosting trains a series of weak learners, each focuses on the errors of the previous one. The residual predictions are multiplied by the learning rate (0.1 here) before added to the average.
Here the picture looks more complicated than the one on regression. The purple ones are log of odds (l). The green ones are probabilities. We firstly calculate log of odds of y, instead of average. We then calculate probabilities using log of odds. We build a regression tree. The leaves are colored green. The leaves have residuals. We use the probability residuals to produce log-of-odds residuals or $\gamma$. $\gamma$ is then used to update l. This continues until we are satisfied with the results or we are running out of iterations.
The Steps
Step 1: Calculate the log of odds of y. This is also the first estimation of y. Here is the number of true values and of false values.
For each , the probability is:
The prediction is:
Step 2 for m in 1 to M:
- Step 2.1: Compute so-call pseudo-residuals:
Step 2.2: Fit a regression tree to pseudo-residuals and create terminal regions (leaves) for
Step 2.3: For each leaf of the tree, there are $p_j$ elements, compute $\gamma$ as following equation.
(In practise, the regression tree will do this for us.)
Step 2.4: Update the log of odds with learning rate $\alpha$:
For each $x_i$, the probability is:
The prediction is:
Step 3. Output
(Optional) From Gradient Boosting to Gradient Boosting Classification
The above knowledge is enough for writing BGR code from scratch. But I want to explain more about gradient boosting. GB is a meta-algorithm that can be applied to both regression and classification. The above one is only a specific form for regression. In the following, I will introduce the general gradient boosting algorithm and deduce GBR from GB.
Let’s first look at the GB steps
The Steps
Input: training set , a differentiable loss function , number of iterations M
Algorithm:
Step 1: Initialize model with a constant value:
Step 2 for m in 1 to M:
- Step 2.1: Compute so-call pseudo-residuals:
Step 2.2: Fit a weak learner to pseudo-residuals. and create terminal regions , for .
Step 2.3: For each leaf of the tree, compute as the following equation.
Step 2.4: Update the model with learning rate $\alpha$:
Step 3. Output
Lost Function:
To deduce the GB to GBC, I simply define a loss function and solve the loss function in step 1, 2.1 and 2.3. We use Log of Likelihood as the loss function:
Since this is a function of probability and we need a function of log of odds(), let’s focus on the middle part and transform it into a function of .
The middle part is:
Since
We put this to the previous equation:
Thus, we will have the loss function over log of odds:
For Step 1:
Because the lost function is convex and at the lowest point where the derivative is zero, we have the following:
And We have: (Here p is the real probability)
Such that, when log(odds)=log(p/(1-p)) or the probability is the real probability, the lost function is minimized.
For Step 2.1
We have already taken the derivative.
For step 2.3:
I apply the lost function:
Let’s focus on the middle part
Let’s use Second Order Taylor Polynomial:
Let’s take the derivate:
(The product rule (ab)’=a’ b+a b’)
Now we have
Code
Firstly, let’s define a data table as follows:
| no | name | likes_popcorn | age | favorite_color | loves_troll2 |
|---|---|---|---|---|---|
| 0 | Alex | 1 | 10 | Blue | 1 |
| 1 | Brunei | 1 | 90 | Green | 1 |
| 2 | Candy | 0 | 30 | Blue | 0 |
| 3 | David | 1 | 30 | Red | 0 |
| 4 | Eric | 0 | 30 | Green | 1 |
| 5 | Felicity | 0 | 10 | Blue | 1 |
Step 1
1 | log_of_odds0=np.log(4 / 2) |
The output is
the log_of_odds is : 0.6931471805599453
the probability is : 0.6666666666666666
the prediction is : 1
Step 2
For Step 2, I define a function called iteration, I will call it several times. Each time we go through from Step 2.1 to Step 2.4.
1 | def iteration(i): |
Now Let’s call iteration 0
1 | iteration(0) |
The output is as follow:
[1 2 2 2 2 1]
for leaf 1, we have 2 related samples. and gamma is 1.5
for leaf 2, we have 4 related samples. and gamma is -0.7499999999999998
| no | name | popcorn | age | color | y | 𝑝0 | 𝑙0 | 𝑟0 | 𝛾0 | 𝑙1 | 𝑝1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Alex | 1 | 10 | Blue | 1 | 0.666667 | 0.693147 | 0.333333 | 1.50 | 1.893147 | 0.869114 |
| 1 | Brunei | 1 | 90 | Green | 1 | 0.666667 | 0.693147 | 0.333333 | -0.75 | 0.093147 | 0.523270 |
| 2 | Candy | 0 | 30 | Blue | 0 | 0.666667 | 0.693147 | -0.666667 | -0.75 | 0.093147 | 0.523270 |
| 3 | David | 1 | 30 | Red | 0 | 0.666667 | 0.693147 | -0.666667 | -0.75 | 0.093147 | 0.523270 |
| 4 | Eric | 0 | 30 | Green | 1 | 0.666667 | 0.693147 | 0.333333 | -0.75 | 0.093147 | 0.523270 |
| 5 | Felicity | 0 | 10 | Blue | 1 | 0.666667 | 0.693147 | 0.333333 | 1.50 | 1.893147 | 0.869114 |

In Iteration 0, Let’s look at each step.
In Step 2.1, We calculate residuals, that is $y-p_0$.
In step 2.2, we fit a regression tree as above.
In step 2.3, we calculate $\gamma$.
- For the first leaf, we have two samples (Alex and Felicity). $\gamma$ is: (1/3+1/3)/((1-2/3)2/3+(1-2/3)2/3)=1.5
- For the second leaf, we have four samples. $\gamma$ is:(1/3-2/3-2/3+1/3)/(4(1-2/3)2/3)=-0.75
In Step 2.4, F(x) is updated.
Now, let’s check another iteration
1 | iteration(1) |
The output is
[1 2 1 1 1 1]
for leaf 1, we have 5 related samples. and gamma is -0.31564962030401844
for leaf 2, we have 1 related samples. and gamma is 1.9110594001952543
| name | popcorn | age | color | y | 𝑝1 | 𝑙1 | 𝑟1 | 𝛾1 | 𝑙2 | 𝑝2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Alex | 1 | 10 | Blue | 1 | 0.869114 | 1.893147 | 0.130886 | -0.315650 | 1.640627 | 0.837620 |
| 1 | Brunei | 1 | 90 | Green | 1 | 0.523270 | 0.093147 | 0.476730 | 1.911059 | 1.621995 | 0.835070 |
| 2 | Candy | 0 | 30 | Blue | 0 | 0.523270 | 0.093147 | -0.523270 | -0.315650 | -0.159373 | 0.460241 |
| 3 | David | 1 | 30 | Red | 0 | 0.523270 | 0.093147 | -0.523270 | -0.315650 | -0.159373 | 0.460241 |
| 4 | Eric | 0 | 30 | Green | 1 | 0.523270 | 0.093147 | 0.476730 | -0.315650 | -0.159373 | 0.460241 |
| 5 | Felicity | 0 | 10 | Blue | 1 | 0.869114 | 1.893147 | 0.130886 | -0.315650 | 1.640627 | 0.837620 |

For Iteration 2, we have two leaves.
For Leaf 1, there are 5 samples. And $\gamma$ is
(0.130886+-0.523270+-0.523270+0.476730+0.130886)/(20.869114(1-0.869114)+30.523270(1-0.523270))=-0.3156498224562022
For Leaf 2, there is only 1 sample. And 𝛾 is 0.476730/(0.523270*(1-0.523270))=1.9110593001700842
Let’s check another iteration
1 | iteration(2) |
The output:
| no | name | popcorn | age | color | y | 𝑝2 | 𝑙2 | 𝑟2 | 𝛾2 | 𝑙3 | 𝑝3 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Alex | 1 | 10 | Blue | 1 | 0.837620 | 1.640627 | 0.162380 | 1.193858 | 2.595714 | 0.930585 |
| 1 | Brunei | 1 | 90 | Green | 1 | 0.835070 | 1.621995 | 0.164930 | -0.244390 | 1.426483 | 0.806353 |
| 2 | Candy | 0 | 30 | Blue | 0 | 0.460241 | -0.159373 | -0.460241 | -0.244390 | -0.354885 | 0.412198 |
| 3 | David | 1 | 30 | Red | 0 | 0.460241 | -0.159373 | -0.460241 | -0.244390 | -0.354885 | 0.412198 |
| 4 | Eric | 0 | 30 | Green | 1 | 0.460241 | -0.159373 | 0.539759 | -0.244390 | -0.354885 | 0.412198 |
| 5 | Felicity | 0 | 10 | Blue | 1 | 0.837620 | 1.640627 | 0.162380 | 1.193858 | 2.595714 | 0.930585 |

Let’s call iteration 3 and 4
1 | iteration(3) |
Now, let’s take a look at the loss and accuracy:
Accuracy:

Loss:
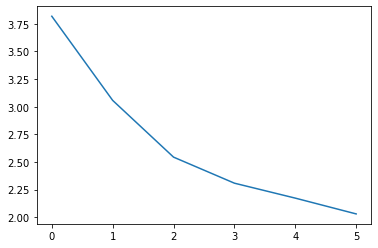
The code is here:
Reference
Gradient Boost Part 3: Classification — Youtube StatQuest
Gradient Boost Part 4: Classification Details — Youtube StatQuest
sklearn.tree.DecisionTreeRegressor — scikit-learn 0.21.3 documentation
Understanding the decision tree structure — scikit-learn 0.21.3 documentation